The RUB (Russia, Ukraine, Belarus) corpus and code website is now online at https://pjbraga.github.io/rub_corpus_and_code/.
RUB Corpus and Code are two downloadable, open-source collections used to assemble and carry out a Russian-language, lexicon-based sentiment analysis.
The RUB Corpus and Code collections are described below.
The RUB Corpus

A snapshot of the RUB Corpus collection.
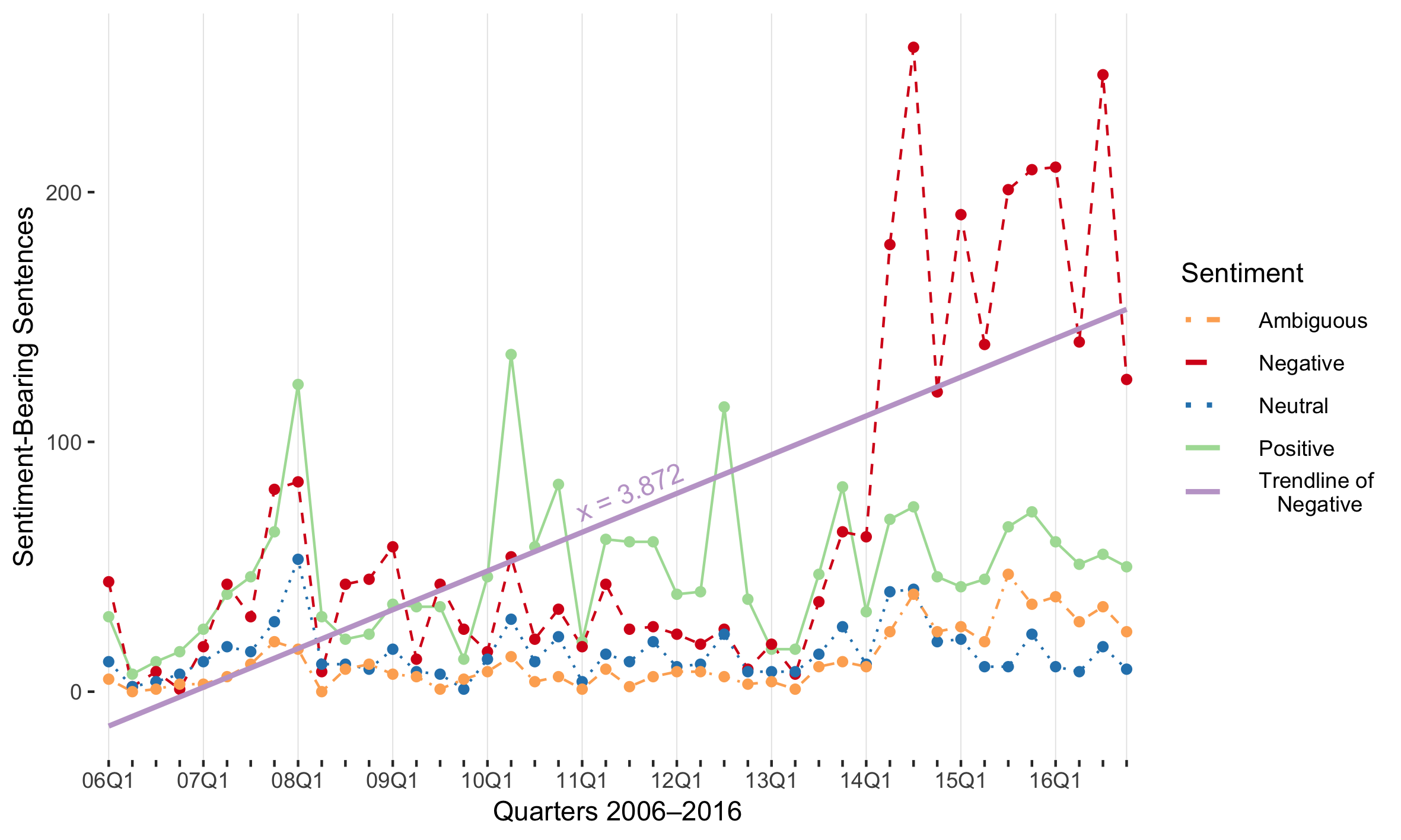
The RUB Corpus is a collection of Russian-language official government speeches, interviews, and press releases made by top policymakers in Russia, Ukraine, and Belarus from 2006 to 2016.
The Corpus consists of three collections of 71,515 Russian-language texts published between 01 January 2006 to 31 December 2016.
A text is sentences spoken by an incumbent president, prime minister, or minister of foreign affairs from a single speech, interview, or official press release on a particular date.
The sources for these texts are online, official government archives.
An example of the RUB Corpus is pictured above. In a country’s corpus dataset, the first column gives a text’s publication date, the second column has corresponding href for the text, and the third column contains the text.
The texts were gathered as part of my PhD dissertation to trace how policymakers’ opinions on particular subjects changed over time.
Tracking what top policymakers say relates to the strong influence leaders and key officials have on policy development in nondemocratic regimes (Ambrosio, 2017, pp. 203–204; Pavlovsky, 2016, pp. 10–16; Rudyj, 2020, p. 198).
The corpus can be used, for example, to analyse the sentiments (positive, negative, neutral, or ambiguous) of Russian-speaking, top policymakers on issues such as NATO, democracy, bilateral relations, and so on.
The code used to carry out this sentiment analysis is described below.
The RUB Code
The Code represents the programs used to compile the RUB Corpus and to conduct a lexicon-based sentiment analysis upon the RUB Corpus.
The second image (below) is a screenshot of a lemmatisation function, which is part of the sentiment analysis Code.

A snapshot of the RUB Corpus and Code sentiment analysis functions.
The sentiment analysis was conducted using a modified version of the lexicon created by Loukachevitch and Levchik (2016).
Access the RUB Corpus and Code
Both the RUB Corpus and Code can be downloaded from their respective website pages. Find the Corpus and Code at https://pjbraga.github.io/rub_corpus_and_code/, or they can be downloaded from the project GitHub repository.
The project website, https://pjbraga.github.io/rub_corpus_and_code/, has detailed overviews of both the RUB Corpus and the Code.
Page References
Ambrosio, T. (2017). The fall of Yanukovych: Structural and political constraints to implementing authoritarian learning. East European Politics, 33(2), 184–209. Available at: https://doi.org/10.1080/21599165.2017.1304382.
Loukachevitch, N. and Levchik, A. (2016). Creating a General Russian Sentiment Lexicon. In Proceedings of Language Resources and Evaluation Conference LREC-2016. Available at: http://www.lrec-conf.org/proceedings/lrec2016/pdf/285_Paper.pdf.
Pavlovsky, G. (2016).</strong> Russian Politics Under Putin: The System Will Outlast the Master. Foreign Affairs, 95(3), 10–17. Available at: https://www.foreignaffairs.com/articles/russia-fsu/2016-04-18/russian-politics-under-putin.
Rudyj, K. V. (2020). “Nepohožie: Vzglâd na Kitaj i belorussko-kitajskie otnošeniâ” [Dissimilar: A Perspective on China-Belarusian Relations]. Zviazda: Minsk, Belarus. Available at: https://oz.by/books/more10931323.html.